Publications
Group highlights
(For a full list of publications see below or go to Google Scholar)

We propose a holistic resource management framework for diversely scaled edge cloud systems that optimizes workload placement and resource allocation across heterogeneous edge and cloud nodes.
Ismet Dagli, Justin Davis, Mehmet E. Belviranli
ACM International Conference on Supercomputing (ICS’25)

We present MC3, a covert channel attack that exploits shared memory contention patterns on heterogeneous System-on-Chips to enable unauthorized communication between isolated processing units.
Ismet Dagli, James Crea, Soner Seckiner, Yuanchao Xu, Selcuk Kose, Mehmet E. Belviranli
Design, Automation & Test in Europe Conference (DATE’25)
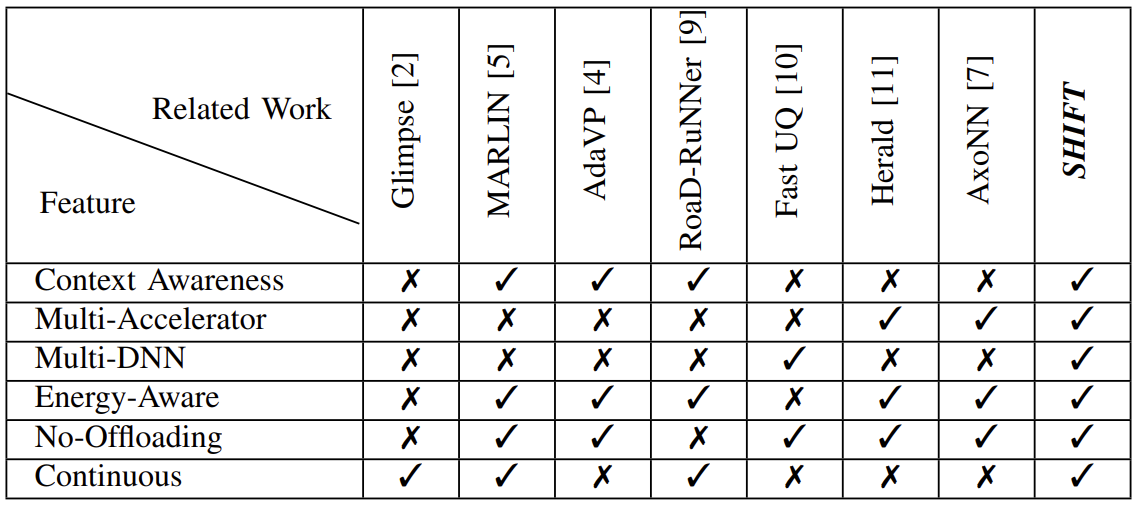
We propose the use of multiple accelerators and many distinct object detection deep neural networks to improve the energy efficiency of continuous object detection scenarios.
Justin Davis, Mehmet E. Belviranli
2024 Design, Automation & Test in Europe Conference & Exhibition
Won outstanding paper in the autonomous system design intiative at DATE24
we propose running neural network (NN) inference on multiple accelerators. Our goal is to provide an energyperformance trade-off by distributing layers in the NN between a performance- and a power-efficient accelerator. We first provide an empirical modeling methodology to characterize execution and inter-layer transition times. We then find an optimal layerto-accelerator mapping, by representing the trade-off as a linear programming optimization constraint.
Ismet Dagli, Alexander Cieslewicz, Jedidiah McClurg, Mehmet E. Belviranli
59th ACM/IEEE Design Automation Conference(2022)
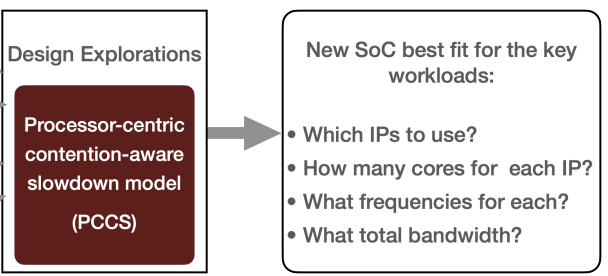
we presents a new approach to this problem, consisting of a novel processor-centric slowdown modeling methodology and a new three-region interference-conscious slowdown model. The modeling process needs no measurement of corunning of various combinations of applications, but the produced slowdown models can be used to estimate the co-run slowdowns of arbitrary workloads on various SoC designs that embed a newer generation of accelerators how that twist angle variation is small over areas of hundreds of nm.
Yuanchao Xu, Mehmet E. Belviranli, Xipeng Shen; Vetter, Jeffrey S
54th Annual IEEE/ACM International Symposium on Microarchitecture(2021)

ParDNN is a novel directed graph partitioning method for memory-constrained DNNs. ParDNN is automatic and generic, needs no intervention, and handles all model types. ParDNN is a lightweight method with a negligible overhead. ParDNN efficiency is experimentally demonstrated with large models using Tensorflow.
Fareed Qararyah, Mohamed Wahib, Doğa Dikbayır, Mehmet E. Belviranli , Didem Unat
Parallel Computing, 2021, 102792, ISSN 0167-8191
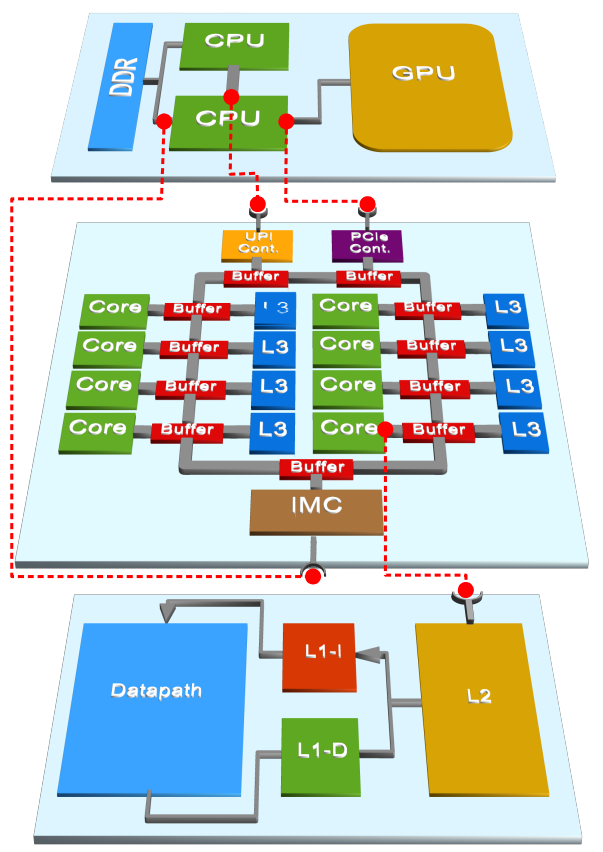
We introduce FLAME, a graph-based machine representation to flexibly model a given hardware design at any desired resolution while providing the ability to refine specific components along the hierarchy. FLAME allows each processing unit in the system to declare its specific capabilities and enables higher level elements to reuse and leverage these declarations to form more complex system topologies. Applications are characterized with the Aspen application model; each component has the ability to report its characteristic behavior for a given application model against a supported metric.
Mehmet E Belviranli, Jeffrey S Vetter
DATE’19, 2019 Design, Automation & Test in Europe Conference & Exhibition
Full List of publications
HARNESS: Holistic Resource Management for Diversely Scaled Edge Cloud Systems
Ismet Dagli, Justin Davis, Mehmet E. Belviranli
ACM International Conference on Supercomputing (ICS’25)
MC3: Memory Contention-Based Covert Channel Communication on Shared DRAM System-on-Chips
Ismet Dagli, James Crea, Soner Seckiner, Yuanchao Xu, Selcuk Kose, Mehmet E. Belviranli
Design, Automation & Test in Europe Conference (DATE’25)
Scheduling for Cyber-Physical Systems with Heterogeneous Processing Units under Real-World Constraints
Justin McGowen, Ismet Dagli, Neil T. Dantam, Mehmet E. Belviranli
ACM International Conference on Supercomputing (ICS’24)
Shared Memory-contention-aware Concurrent DNN Execution for Diversely Heterogeneous SoCs
Ismet Dagli, Mehmet E. Belviranli
ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP’24)
Exploring Page-based RDMA for Irregular GPU Workloads
Benjamin Wagley, Pak Markthub, James Crea, Bo Wu, Mehmet E. Belviranli
GPGPU Workshop at PPoPP’24
A Runtime Manager Integrated Emulation Environment for Heterogeneous SoC Design with RISC-V Cores
Hasan Umut Suluhan, Serhan Gener, Alexander Fusco, Joshua Mack, Ismet Dagli, Cagatay Edemen, Ali Akoglu, Mehmet E. Belviranli
IPDPS Workshops’24
Contention-aware Performance Modeling for Heterogeneous Edge and Cloud Systems
Ismet Dagli, Andrew Depke, Andrew Mueller, Md Sahil Hassan, Ali Akoglu, Mehmet E. Belviranli
FRAME Workshop at HPDC’23
Constraint-Aware Resource Management for Cyber-Physical Systems
Justin McGowen, Ismet Dagli, Neil T. Dantam, Mehmet E. Belviranli
Design, Automation & Test in Europe Conference - Work in Progress (DATE’24 WiP)
Context-aware Multi-Model Object Detection for Diversely Heterogeneous Compute Systems
Justin Davis, Mehmet E. Belviranli
2024 Design, Automation & Test in Europe Conference & Exhibition
AxoNN: Energy-Aware Execution of Neural Network Inference on Multi-Accelerator Heterogeneous SoCs
Ismet Dagli, Alexander Cieslewicz, Jedidiah McClurg, Mehmet E. Belviranli
59th ACM/IEEE Design Automation Conference(2022)
PCCS: Processor-Centric Contention-aware Slowdown Model for Heterogeneous System-on-Chips
Yuanchao Xu, Mehmet E. Belviranli, Xipeng Shen; Vetter, Jeffrey S
54th Annual IEEE/ACM International Symposium on Microarchitecture(2021)
Multi-accelerator Neural Network Inference in Diversely Heterogeneous Embedded Systems
Ismet Dagli; Mehmet E. Belviranli
2021 IEEE/ACM Redefining Scalability for Diversely Heterogeneous Architectures Workshop (RSDHA)
A computational-graph partitioning method for training memory-constrained DNNs
Fareed Qararyah, Mohamed Wahib, Doğa Dikbayır, Mehmet E. Belviranli , Didem Unat
Parallel Computing, 2021, 102792, ISSN 0167-8191
MEPHESTO: Modeling Energy-Performance in Heterogeneous SoCs and Their Trade-Offs
MAH Monil, ME Belviranli, S Lee, JS Vetter, AD Malony
PACT’21, Proceedings of the ACM International Conference on Parallel Architectures and Compilation Techniques
FLAME: Graph-based hardware representations for rapid and precise performance modeling
Mehmet E Belviranli, Jeffrey S Vetter
DATE’19, 2019 Design, Automation & Test in Europe Conference & Exhibition
DRAGON: breaking GPU memory capacity limits with direct NVM access
Pak Markthub, Mehmet E Belviranli, Seyong Lee, Jeffrey S Vetter, Satoshi Matsuoka
SC’18, International Conference for High Performance Computing, Networking, Storage and Analysis
Designing Algorithms for the EMU Migrating-threads-based Architecture
Mehmet E Belviranli, Seyong Lee, Jeffrey S Vetter
2018 HPEC, IEEE High Performance extreme Computing Conference
Juggler: a dependence-aware task-based execution framework for GPUs
PPoPP’18, Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming
Wireframe: Supporting data-dependent parallelism through dependency graph execution in gpus
AmirAli Abdolrashidi, Devashree Tripathy, Mehmet Esat Belviranli, Laxmi Narayan Bhuyan, Daniel Wong
MICRO-50 ‘2017, Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture
CuMAS: Data Transfer Aware Multi-Application Scheduling for Shared GPUs
Mehmet E Belviranli, Farzad Khorasani, Laxmi N Bhuyan, Rajiv Gupta
ICS’16, Proceedings of the 2016 International Conference on Supercomputing
Stadium hashing: Scalable and flexible hashing on gpus
Farzad Khorasani, Mehmet E Belviranli, Rajiv Gupta, Laxmi N Bhuyan
PACT’15, 2015 International Conference on Parallel Architecture and Compilation
PeerWave: Exploiting Wavefront Parallelism on GPUs with Peer-SM Synchronization
Mehmet E Belviranli, Peng Deng, Laxmi N Bhuyan, Rajiv Gupta, Qi Zhu
ICS’15, Proceedings of the 29th ACM on International Conference on Supercomputing
A paradigm shift in GP-GPU computing: task based execution of applications with dynamic data dependencies
Mehmet E Belviranli, Chih-Hsun Chou, Laxmi N Bhuyan, Rajiv Gupta
https://dl.acm.org/doi/abs/10.1145/2608020.2608024
Thermal prediction and scheduling of network applications on multicore processors
Chih-Hsun Chou, Mehmet E Belviranli, Laxmi N Bhuyan
Architectures for Networking and Communications Systems
A dynamic self-scheduling scheme for heterogeneous multiprocessor architectures
Mehmet E Belviranli, Laxmi N Bhuyan, Rajiv Gupta
TACO’13, ACM Transactions on Architecture and Code Optimization
CiSE: A circular spring embedder layout algorithm
Ugur Dogrusoz, Mehmet E. Belviranli, Alptug Dilek
IEEE Transactions on Visualization and Computer Graphics
VISIBIOweb: visualization and layout services for BioPAX pathway models
Alptug Dilek, Mehmet E. Belviranli, Ugur Dogrusoz
Nucleic Acids Research, Volume 38