Ongoing Federal and Privately Funded Research
Robust Enforcement of Customizable Resource Constraints in Heterogeneous Embedded Systems We develop an approach which enables embedded systems development with respect to customizable constraints on system-wide resource usage (time, energy, etc.). We utilize formal methods to develop a unified approach which addresses issues arising due to the trade-offs between computation, actuation, and sensing in embedded systems. This project is funded by National Science Foundation (NSF).
Smarter Nanoelectronics with Atomically Precise Graphene Nanoribbons (GNRs) We explore new ways to improve graphene nanoribbon (GNR) material synthesis involving ribbon length and to enhance single-device-level performance by exploiting novel GNR heterostructure systems (i.e., seamless lateral metal-semiconductormetal GNR junctions). This project is funded by Semiconductor Research Corporation (SRC).
Modeling the Memory-Compute Gap in Large-scale Superconductive Systems We develop circuit, microarchitectural simulation, and analytical models for the large-scale integration of Josephson-CMOS hybrid memories. This model will consider the high frequency nature of SFQ logic and explore strategies for improving memory interactions while reducing power consumption. This project is funded by the Department of Energy (DoE).
Research Projects
Low latency motion tracking for Autonomous Discovery Drones
Autonomous Discovery & Intercept missions can provide valuable intel against an adversary. While prior work has been completed into individual parts of such a system, there is no open established framework for this task. As such there is a need for a former framework to be developed, that can serve as the basis for further research. This project builds a framework for an autonomous interception drone. Included in this framework are a physical and simulated test platform as well as the detection and control software for this scenario.
CloudRenderVR: Motion-prediction based Speculative Cloud rendering for VR platforms The project spans three components: The server, to render frames and update the game world. The model, to predict future human motion to allow for preemptive rendering. And, the client, to record pose data and communicate with both the server and the model.
Graph-based analytical computation models for autonomous software and heterogeneous hardware In this project, we build FLAME, a graph-based machine representation to flexibly model a given hardware design at any desired resolution while providing the ability to refine specific components along the hierarchy. FLAME allows each processing unit in the system to declare its specific capabilities and enables higher level elements to reuse and leverage these declarations to form more complex system topologies.
Scheduling in heterogeneous architectures:
Balancing performance/energy trade-off in energy-limited systems:
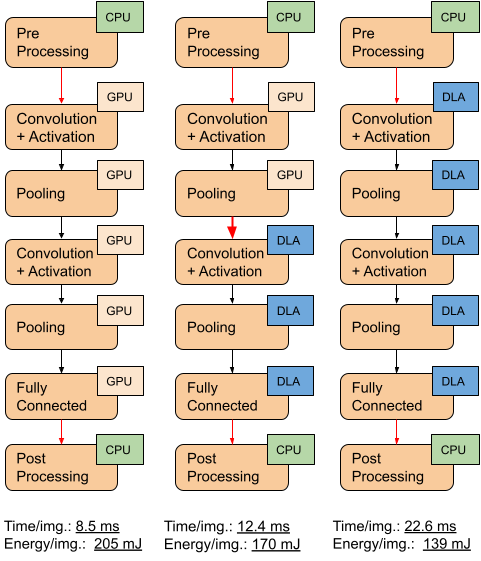 We work on running neural network (NN) inference on multiple accelerators of an SoC. Our goal is to enable an energy-performance trade-off with an by distributing layers in a NN between a performance- and a power-efficient accelerator. We first provide an empirical modeling methodology to characterize execution and inter-layer transition times. We then find an optimal layers-to-accelerator mapping by representing the trade-off as a linear programming optimization constraint. We evaluate our approach on the NVIDIA Xavier AGX SoC with commonly used NN models. We use the Z3 SMT solver to find schedules for different energy consumption targets, with up to 98% prediction accuracy.
We work on running neural network (NN) inference on multiple accelerators of an SoC. Our goal is to enable an energy-performance trade-off with an by distributing layers in a NN between a performance- and a power-efficient accelerator. We first provide an empirical modeling methodology to characterize execution and inter-layer transition times. We then find an optimal layers-to-accelerator mapping by representing the trade-off as a linear programming optimization constraint. We evaluate our approach on the NVIDIA Xavier AGX SoC with commonly used NN models. We use the Z3 SMT solver to find schedules for different energy consumption targets, with up to 98% prediction accuracy.
- Multiple workload scheduling in heterogeneous architectures: We investigate Multi-accelerator Execution (MAE) on diversely heterogeneous embedded systems, where sub-components of a given workload, such as neural network inference, can be assigned to different type of accelerators to achieve a desired latency or energy goal. We first analyze the energy and performance characteristics of execution of neural network layers on different type of accelerators. We then explore energy/performance trade-offs via layer-wise scheduling for neural network inference by considering different layer-to-accelerator mappings.
Computation-Aware Planning in Autonomous Systems
 Hardware-CPS representation for performance modelling: Many cyber-physical systems (CPS) such as robots and self-driving cars pose strict timing requirements to avoid failure.These time-critical requirements limit the operating conditions of the system—e.g., driving slowly to ensure sufficient braking time to avoid a crash. We propose the creation of a structured system, the Constrained Autonomous Workload Scheduler (CAuWS). By using a representative language (AuWL), Timed Petri nets, and mixed-integer linear programming, CAuWS offers novel capabilities to represent and schedule many types of heterogeneous CPSs, real world constraints, and optimization criteria, creating a schedule of the optimal assignment of processors to tasks. This structured and general approach differs from current ad-hoc approaches which are either created for specific optimization criteria, architectures, or CPSs; or which don’t consider physical constraints.
Hardware-CPS representation for performance modelling: Many cyber-physical systems (CPS) such as robots and self-driving cars pose strict timing requirements to avoid failure.These time-critical requirements limit the operating conditions of the system—e.g., driving slowly to ensure sufficient braking time to avoid a crash. We propose the creation of a structured system, the Constrained Autonomous Workload Scheduler (CAuWS). By using a representative language (AuWL), Timed Petri nets, and mixed-integer linear programming, CAuWS offers novel capabilities to represent and schedule many types of heterogeneous CPSs, real world constraints, and optimization criteria, creating a schedule of the optimal assignment of processors to tasks. This structured and general approach differs from current ad-hoc approaches which are either created for specific optimization criteria, architectures, or CPSs; or which don’t consider physical constraints.
Direct NVMe Accesses for GPU
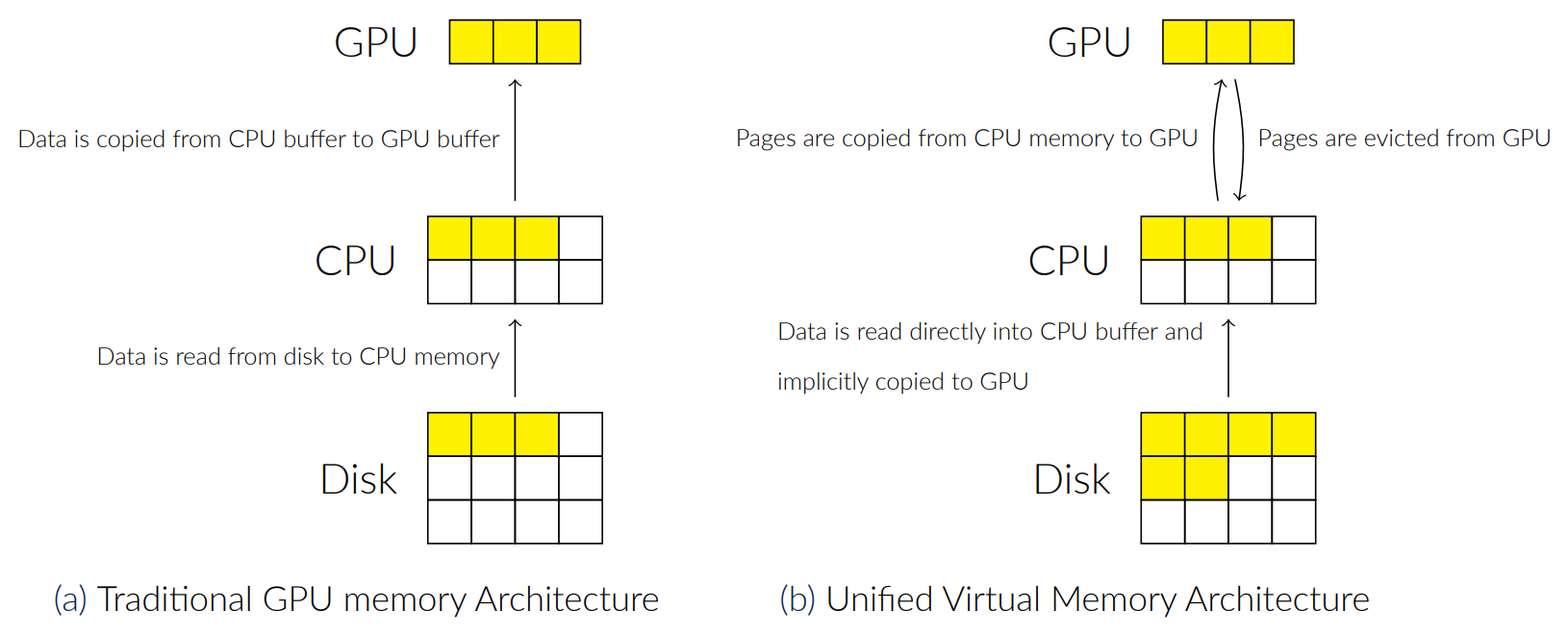 Managing memory in GPU accelerated workloads is a difficult task especially as dataset sizes grow beyond available host memory on an ndividual system. On traditional GPU memory architectures if data is larger than GPU memory, the user must process their data in batches, adding complexity to the task. Architectures like NVIDIA’s Unified Virtual Memory (UVM) allow for users to allocate GPU memory across CPU and GPU memory, removing the limitations that data must be smaller than GPU memory. However, UVM still limits data sizes to be smaller than the combined CPU and GPU memory on the system. DRAGON expands on UVM by utilizing high speed NVMe storage and UVM’s pagefaulting subsystem, in an mmap-like interface that allows terabyte-scale data processing on GPUs. This brings out-of-core processing to any CUDA application. Since DRAGON is implemented at the driver level, it requires no changes to CUDA kernel logic. DRAGON catches page-faults from the UVM driver, and ensures that the required page is copied into GPU memory for use by the application.
Managing memory in GPU accelerated workloads is a difficult task especially as dataset sizes grow beyond available host memory on an ndividual system. On traditional GPU memory architectures if data is larger than GPU memory, the user must process their data in batches, adding complexity to the task. Architectures like NVIDIA’s Unified Virtual Memory (UVM) allow for users to allocate GPU memory across CPU and GPU memory, removing the limitations that data must be smaller than GPU memory. However, UVM still limits data sizes to be smaller than the combined CPU and GPU memory on the system. DRAGON expands on UVM by utilizing high speed NVMe storage and UVM’s pagefaulting subsystem, in an mmap-like interface that allows terabyte-scale data processing on GPUs. This brings out-of-core processing to any CUDA application. Since DRAGON is implemented at the driver level, it requires no changes to CUDA kernel logic. DRAGON catches page-faults from the UVM driver, and ensures that the required page is copied into GPU memory for use by the application.